
目次
はじめに
Linuxシステムは、多言語対応や地域ごとの表記ルールの変更が可能です。これを支えている仕組みが「国際化(i18n)」と「ローカライゼーション(l10n)」です。
この記事では、それらの基礎と、システムでのロケール設定や文字コード(UTF-8など)の扱い方、そして LANG=C が意味することまでを丁寧に解説します。
1. 国際化(i18n)とローカライゼーション(l10n)とは?
| 概念 | 内容 |
|---|---|
| 国際化 (i18n) | 「internationalization」の略で、ソフトウェアを多言語対応可能にする設計段階のこと(英語の間に18文字あるため i18n)。 |
| ローカライゼーション (l10n) | 「localization」の略で、特定言語や文化に合わせて翻訳や日付形式などを変更すること(英語の間に10文字あるため l10n)。 |
たとえば、日本語化されたLinuxシステムでは、コマンドの出力やエラーメッセージも日本語になります。
2. ロケール(locale)とは?
ロケールは、「言語 + 地域 + 文字コード」の組み合わせで、日付・通貨・数字・メッセージの表記方法を定義する環境変数です。
よく使われるロケールの例
| ロケール | 言語 | 地域 | 文字コード |
|---|---|---|---|
en_US.UTF-8 | 英語 | アメリカ | UTF-8 |
ja_JP.UTF-8 | 日本語 | 日本 | UTF-8 |
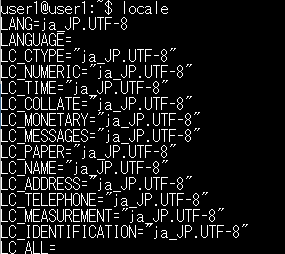
現在のロケールを確認する
locale
ロケールの設定(環境変数)
| 環境変数 | 用途 |
|---|---|
LANG | 基本ロケールを設定(全体の初期値) |
LC_ALL | 全てのロケール設定を一時的に上書き |
LC_* | 特定カテゴリ(日時、数字、メッセージなど)を個別設定 |
一時的に英語モードにする(例:スクリプトで)
LANG=C ls
LANG=C:ロケールを「C(POSIX標準)」に設定- 英語&ASCIIで出力されるため、スクリプトやデバッグで文字化けを防げるという利点あり。
3. ロケールの生成と変更
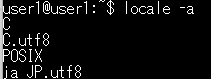
ロケールの一覧表示
locale -a
ロケールの生成(Debian/Ubuntu)
sudo locale-gen ja_JP.UTF-8
sudo update-locale LANG=ja_JP.UTF-8
ロケールの生成(RHEL/CentOS)
localedef -f UTF-8 -i ja_JP ja_JP.UTF-8
4. 文字コードの変換(iconv)
Linuxでは複数の文字コードが扱えます。特に重要なのは以下の4つ:
| 文字コード | 特徴 |
|---|---|
| UTF-8 | Unicode対応。現在の主流 |
| ISO-8859-1 | ラテン文字圏向け |
| ISO-2022-JP | 日本語用のメールでよく使用 |
| ASCII | 英語圏の最小限文字 |
文字コード変換コマンド:iconv
iconv -f SHIFT_JIS -t UTF-8 input.txt -o output.txt
-f:変換元の文字コード-t:変換先の文字コード
5. ローカライゼーションの実践例
スクリプトで英語に強制切り替え(デバッグ向け)
#!/bin/bash
LANG=C df -h # 日本語だとエラーメッセージが処理できない場合などに有効
.bashrcでロケールを設定
export LANG=ja_JP.UTF-8
export LC_ALL=ja_JP.UTF-8
まとめ:ローカライゼーションを理解すると得られる利点
- 多国籍チームでの開発でも環境が統一しやすい
- エラーや警告が英語で標準化されることで、Web検索での情報が見つけやすい
- ログやスクリプト処理が安定する
よくある質問(FAQ)
Q1. LANG=Cって何の意味があるの?
→ ロケールを「C」(標準環境)に設定し、出力を英語・ASCIIに限定することでスクリプトや自動処理での文字化け防止になる。
Q2. LC_ALLとLANGはどちらを使えばいい?
→ 一時的なロケール上書きにはLC_ALLを使い、基本設定にはLANGを使います。
Q3. 文字化けするファイルはどうする?
→ iconvでUTF-8に変換しましょう。
コメント